— November 22, 2018

qimono / Pixabay
You regularly run A/B tests on the design of a pop-up. You have a process, implement it correctly, find statistically significant winners, and roll out winning versions sitewide.
Your tests answer every question except one: Is the winning version still better than never having shown a pop-up?
A hold-out group can deliver the answer, but, like everything, it comes at a cost.
What are hold-out groups?
A hold-out group is a form of cross-validation that extracts, or “holds out,” one set of users from testing. You can run holdouts for A/B tests and other marketing efforts, like drip email campaigns in which a percentage of users receives no email at all.
After completion of a test and implementation of the winning version, the hold-out group remains for weeks, months, or, in rare cases, years. In doing so, the holdout attempts to quantify “lift”—the increase in revenue compared to doing nothing.
For example, a “10% off” coupon (delivered through a pop-up or email campaign) may generate 15% more sales than a current “$ 10 off a $ 100 purchase” coupon. However, without a holdout, you don’t know how many consumers would’ve bought without any coupon at all—a winning test may still reduce profits.
Most often, however, holdouts are used not to measure lift from a single test but lift for an entire experimentation program. Because holdouts require siphoning off a statistically relevant portion of an audience, they make sense only for sites with massive amounts of traffic.
The difference between a hold-out and a control group
Imagine you want to test a headline on a product page. The version on the left (Control) is the current version, while the experimental version (Variation A) is on the right:

Assume, by some miracle, that Variation A performs better, and you implement it for all visitors. That’s the standard process for an A/B split test—50% see each version during the test, and 100% see the winning version after the test completes.
However, if you continue to show some visitors the control version, that control group becomes the holdout. In other tests, the control may not “transition” from control to holdout. Instead, it can be a separate segment omitted from the start—like the email campaign in which a percentage of subscribers receive nothing.
Because a holdout can estimate the value of a marketing effort beyond a relative improvement between two versions, some consider it “the gold standard” in testing.
Why hold-out groups are “the gold standard”
For many, holdouts are a gold standard for testing because they measure the value not just of a test but of a testing program.
And while the value of testing may be apparent to those involved in it, individual test results do not aggregate into ROI calculations made in the C-Suite. There, the considerations extend beyond website KPIs:
- Does it make sense to employ a team of data scientists or email marketers?
- If we fired the entire team tomorrow, what would happen?
Holdouts also have the potential to assess experimentation’s impact on customer lifetime value. While a short-term split test may record an increase in clicks, form fills, or sales, it doesn’t capture the long-term effects:
- Do pop-ups and sticky bars increase email leads but, over time, reduce return visitors?
- Does a coupon program ultimately decrease purchases of non-discounted items?
Some effects may take months or years to materialize, accumulating confounding factors daily. Thus, when it comes to measuring the long-term impact of tests, how long is long enough?
Defining the scope for hold-out groups
How long should you maintain a hold-out group? Without a defined window, you could make ludicrous comparisons, like decades-long holdouts to measure your current site against its hand-coded version from the late 1990s.
The decisions in the extreme are laughable, but as the gap narrows—five years, three years, one year, six months—they get harder.
Look-back windows and baselines for holdouts
How much time should pass before you update the “baseline” version of your site for a hold-out group? “It depends on your goals,” CXL Founder Peep Laja explained. “You could leave it unchanged for three years, but if you want to measure the annual ROI, then you’d do yearly cycles.”
What about the degree of site change? “When it’s functionality, there’s a sense of permanence,” Cory Underwood, a Senior Programmer Analyst at L.L. Bean, told me. “When it’s messaging, you get into how effective and for how long it will be effective.”
Underwood continued:
There are times when you would want to get a longer read. You can see this in personalization. You target some segment with a completely different experience on the range of “never” to “always.” Say it won and you flip it to always. Six months later, is it still driving the return?
A hold-out group offers an answer. (So, too, Laja noted, could re-running your A/B test.) But you wouldn’t get an apples-to-apples comparison unless you accounted for seasonality between the two time periods.
In that way, a hold-out group is uniquely rewarding and challenging: It may mitigate seasonality in a completed A/B test but reintroduce it when comparing the hold-out group to the winner.
Omnichannel retailers like L.L. Bean manage further complexity: Demonstrating that website changes have a long-term positive impact on on-site behavior and offline activity. The added variables can extend the timeline for holdouts. Underwood has run hold-out groups for as long as two years (an anomaly, he conceded).
For test types and timelines that merit a hold-out group, implementation has its own considerations.
Implementing hold-out groups for tests
The implementation of holdouts isn’t formulaic. Superficially, it involves dividing your audience into one additional segment. (Hold-out segments often range from 1 to 10% of the total audience.) For example:
Control: Audience 1 (47.5%)
Variation A: Audience 2 (47.5%)
Hold-out: Audience 3 (5%)
Many A/B testing tools allow users to adjust weights to serve (or not serve) versions of a test to an audience. But not every test can take advantage of segmentation via testing platforms.
As Underwood explained, a decision to roll out tests on the client side (using a testing tool) versus server side (through a CDN) hinges on two considerations:
- The scale of change. Large-scale DOM manipulations deployed via client-side rollouts risk a slow and glitchy user experience. The greater the difference between versions of the site involved in a test (like a hold-out that preserves an entirely different homepage design), the more that server-side delivery makes sense.
- The specificity of targeting. Testing tools connect user data with CRM data for more granular targeting; server-side segmentation can be limited to broader attributes of anonymous users, such as location and device type, making it difficult to test changes for a narrowly targeted audience.
At a certain scale—say, for Pinterest’s quarter-billion monthly users—building a custom platform can expedite testing and integrate more effectively with in-house tools.

Pinterest built its own A/B testing platform to support more than 1,000 simultaneous tests. (Image source)
Perhaps most importantly, profitable implementation depends on knowing when a hold-out group improves a website—and when it’s a costly veneer to hide mistrust in the testing process.
When holdouts work
1. For large-scale changes
To the site. The more expensive a change will be to implement, the greater the justification to use a hold-out group before implementation.
After-the-fact holdouts for a non-reversible change make little sense. But advance testing to validate the long-term effect does. “As the risk goes up, the likelihood [of a holdout] also goes up,” summarized Underwood.
Often, Underwood said, marketing teams request holdouts to validate proposals for extensive site changes. A holdout that confirms the long-term value of their plans is persuasive to those who sign-off on the investment.
To team priorities. John Egan, the Head of Growth Traffic Engineering at Pinterest, agrees with Underwood—a test that implicates larger changes deserves greater (or, at least, longer) scrutiny, which a holdout delivers.
But site development costs aren’t the only costs to consider. As Egan explained, holdouts also make sense when “there is an experiment that was a massive win and, as a result, will potentially cause a shift in the team’s strategy to really double down on that area.”
In those circumstances, according to Egan, a holdout typically lasts three to six months. That length is “enough time for us to be confident that this new strategy or tactic does indeed drive long-term results and doesn’t drive a short-term spike but long-term is net-negative.”
2. To measure the untrackable
Egan acknowledged that, while holdouts are standard at Pinterest, “we only run holdout tests for a small percentage of experiments.”
For Pinterest, the primary use case is to:
measure the impact of something that is difficult to fully measure just through tracking. For instance, we will run periodic holdouts where we turn off emails/notifications to a small number of users for a week or a month to see how much engagement emails/notifications drive and their impact on users’ long-term retention.
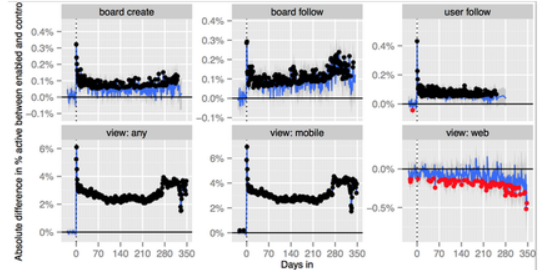
Egan detailed such an instance on Medium. His team wanted to test the impact of adding a badge number to push notifications. Their initial A/B test revealed that a badge number increased daily active users by 7% and boosted key engagement metrics.

Badge numbers drove a near-term lift, but would that lift endure? Egan’s team used a hold-out group to find out. (Image source)
Still, Egan wondered, “Is badging effective long-term, or does user fatigue eventually set in and make users immune to it?” To find out, Pinterest created a 1% hold-out group while rolling out the change to the other 99% of users.
The result? The initial 7% lift faded to 2.5% over the course of a year—still positive but less dramatic than short-term results forecasted. (A subsequent change to the platform elevated the lift back to 4%.)

The badging group continued to outperform the hold-out group after more than a year, albeit less dramatically than initial test results showed. (Image source)
The takeaway for Egan was clear: “In general, holdout groups should be used anytime there is a question about the long-term impact of a feature.”
3. To feed machine learning algorithms
Today, a Google search on “hold-out groups” is more likely to yield information for training machine learning algorithms than validating A/B tests. The two topics are not mutually exclusive.
As Egan explained, holdouts for machine learning algorithms, “gather unbiased training data for the algorithm and ensure the machine learning algorithm is continuing to perform as expected.”
In this case, a hold-out is an outlier regarding look-back windows: “The holdouts for machine learning algorithms run forever.”
These use-cases make sense, but all come with costs, which can quickly multiply:
- Teams spend time identifying a hold-out segment.
- Teams spend time maintaining the hold-out version of the website.
- A portion of the audience doesn’t see a site change that tested better.
In some cases, the justification for a hold-out group derives not from a commitment to rigorous testing but from methodological mistrust.
When holdouts skirt the larger issue
Tim Stewart, who runs trsdigital, is usually “setting up testing programs or rescuing them.” The latter, he noted, is more common.
As a consultant, he often meets directly with the C-Suite, a privilege many in-house optimization teams don’t enjoy. That access has made him a skeptic of using holdouts: “With holdouts, the answer to ‘Why?’ seems to be ‘We don’t trust our tests.’”
Stewart isn’t a full-blown contrarian. As he told me, he recognizes the benefits of hold-out groups to identify drop-offs from the novelty effect, monitor the cumulative effect of testing, and other rationales detailed previously.
But too often, Stewart continued, holdouts support statistically what teams fail to support relationally—the legitimacy of their process:
I understand what [CEOs] want. But testing does not give you an answer. It gives you a probability that the decision you make is in the right direction. Each one individually is only so useful. But if you structure a set of questions, the nth cumulative effect of learning and avoiding risk is worthwhile. That’s the faith-based part of it.
In other words, a valid testing process diminishes the need for holdouts. Running those tests, Stewart said, is:
a lot of money and effort and caveats [that] defers any kind of responsibility of explaining it to the business. For proving the business value, you should be proving it in other ways.
That’s especially true given the opportunity costs.
The opportunity costs of holdouts
Testing resources are limited, and using resources for holdouts slows the rate of testing. As Amazon’s Jeff Bezos declared, “Our success at Amazon is a function of how many experiments we do per year, per month, per week, per day.”
Opportunity costs can rise exponentially due to the complexity of managing hold-out groups, which businesses often underestimate.
Stewart has an analogy: Imagine a pond. Toss a large paving stone into the pond. How hard would it be to measure the size and effect of the ripples? Not too hard.
Now imagine throwing handfuls of pebbles into the ocean. What effect does each pebble have? How do you account for the incessant waves? Or adjust your estimates for the tides? Or during a hurricane?
In marketing, the confounding factors that make it difficult to measure the impact of each pebble (read: test) include offline marketing campaigns or macroeconomic changes.
Can a hold-out group still provide an answer? Yes. But at what cost? As Stewart asked: What’s the ROI of statistical certainty measured to three decimal places instead of two if your control isn’t much of a control?
At a certain point, too, you need to include yet another variable: The impact on ROI from using holdouts to measure ROI. And, still, all this assumes that creating a hold-out group is feasible.
The illusion of feasibility
“There is no true hold-out,” Stewart contended. “Even on a control, there are some people who come in on different devices.” (Not to mention, Edgar Å pongolts, our Director of Optimization at CXL, added, users with VPNs and Incognito browsers.)
Holdouts exacerbate the challenges of multi-device measurement: The longer a test runs, the more likely it is that someone deletes a cookie and ends up crossing from a “no test” to “test” segment. And every effort to limit sample pollution increases the costs—which slows the rollout of other tests.
Say you want to go down the rabbit hole to determine the ROI of a testing program—cost is no factor. As Stewart outlined, you’d need to do more than just hold out a segment of visitors from an updated site.
You’d need to withhold all test results from a parallel marketing team and, since websites are never static, allow them to make changes to the hold-out version based on gut instinct. Stewart has presented executives with that very scenario:
What we actually have to have is a holdout that includes all of our bad ideas and our good ideas. It’s not holding an audience—it’s running a site without the people who are making the changes seeing any of the test results. Why would we do that?! My point exactly.
Stewart doesn’t make his argument to eschew all use of holdouts. Instead, he aims to expose the misguided motivations that often call for it. Every test result offers probability, not certainty, and using hold-out groups under the false pretense that they’re immune to the ambiguities that plague other tests is naive—and wasteful.
A holdout doesn’t free analysts from dialogue with management, nor should management use a hold-out result to “catch out” teams or agencies when, from time to time, a test result fails to deliver on its initial promise.
“It’s not really about the math,” Stewart concluded. “It’s about the people.”
Conclusion
“Can you do it easily, cheaply, and with enough of your audience?” asked Stewart. Underwood and Egan have done it, but not because of testing efficiency alone.
Both have earned the autonomy to deploy holdouts sparingly. Their body of work—test after test whose results, months and years down the road, continue to fall within the bounds their initial projections—built company-wide faith in their process.
Top-down trust in the testing process focuses the use of holdouts on their proper tasks:
- Unearthing the easily reversible false positives that short-term tests periodically bury.
- Confirming the long-term value of a high-cost change before investing the resources.
Digital & Social Articles on Business 2 Community
(143)
Report Post





