Online transactions have shot up exponentially and so have cases of online fraud. The Consumer Sentinel Network maintained by FTC received 3.2 million reports of identity theft and online fraud in 2019. With fraudsters becoming more adept at finding and exploiting loopholes in systems, fraud management has turned painful for the banking and finance industry. Thankfully, machine learning for fraud detection has come to the rescue of financial organizations.
Machine learning has been instrumental in solving some of the important business problems such as detecting email spam, focused product recommendation, accurate medical diagnosis etc. The adoption of machine learning (ML) has been accelerated with increasing processing power, availability of big data and advancements in statistical modeling.
Data scientists have been successful in authenticating transactions with machine learning and predictive analytics. Automated fraud screening systems powered by machine learning can help businesses in reducing fraud.
FRAUD DETECTION GONE WRONG – HUMAN REVIEW AND TRANSACTION RULES
According to Fraud Benchmark Report by cybersource 83% of North American businesses conduct manual reviews, and on an average, they review 29% of orders manually. Involvement of humans gives insights about fraud patterns and genuine customer behavior. These insights can fine tune automated screening rules. But the manual review is costly, time-consuming and leads to high false negatives.
Due to low confidence in automated solutions, manual review staff accounts for the substantial amount of their fraud management budget. Businesses must invest in exhaustive training for employees working on the manual review. Training the personnel to manually review transactions is time-consuming and expensive.
Manual reviews also increase the time required to fulfill the order. Customer frustration can creep in for services such as digit and software where the customer needs a quick solution.
Over 90% of online fraud detection platforms use transaction rules to direct suspicious transactions through to human review. Surprisingly this traditional approach of using rules or logic statements to query transactions is still used by some banks and payment gateways. The “rules” in this platform use a combination of data and horizon-scanning. The results of this process are generally binary labeling the transactions as authentic or fraud.
The major disadvantage of the traditional process is the occurrence of false positives. This means completely normal customers just looking to make a purchase will go away from your business. The judgment is dependent on individual training and transaction guidelines, which vary depending on the business.
There will be high rates of false positives if the employees reject every transaction above a certain risk threshold, or if it is cheaper to lose a sale than having a fraudulent transaction. A false positive not only affects the sale in the process but also lifetime value generated from the customer. Thus manual reviews based on rules should be the last line of defense in the fraud detection strategy.
Criminal gangs also use malware and phishing emails as a means to compromise customers’ security and personal details. Once obtained, fraudsters will use these details to access customer accounts or to commit fraud. These methods all aim to compromise customers’ personal and financial details, including card data, in order to enable the criminals to commit fraud. Here, the card data used is legitimate but not under the consent of the owner. In these cases, such rules and human review would fail to block transactions.
UNDERSTANDING MACHINE LEARNING FOR FRAUD DETECTION
Machine learning is the science of designing and applying algorithms that are able to learn things from past cases. It uses complex algorithms that iterate over large data sets and analyze the patterns in data. The algorithm facilitates the machines to respond to different situations for which they have not been explicitly programmed. It is used in spam detection, image recognition, product recommendation, predictive analytics etc.
Significant reduction of human effort is the main aim of data scientists in implementing ML. Even with modern analytics tools, it takes a lot of time for humans to read, collect, categorize and analyze the data. ML teaches machines to identify and gauge the importance of patterns in place of humans. Particularly for use cases where data must be analyzed and acted upon in a short amount of time, having the support of machines allows humans to be more efficient and act with confidence.
Machine Learning converts data intensive and confusing information into a simple format that suggests actions to decision makers. A user further trains the ML system by continually adding data and experience. Thus at its core, machine learning is a 3-part cycle i.e. Train-Test-Predict. Optimizing the cycle can make predictions more accurate and relevant to the specific use-case.
WHY SHOULD WE USE MACHINE LEARNING IN FRAUD DETECTION?
Machines are much better than humans at processing large datasets. They are able to detect and recognize thousands of patterns on a user’s purchasing journey instead of the few captured by creating rules. We can predict fraud in a large volume of transactions by applying cognitive computing technologies to raw data. This is the reason why we use machine learning in finance to prevent fraud for our clients. The three factors which explain the importance of machine learning services are –
- Speed – In rule-based systems, people create ad hoc rules to determine which types of orders to accept or reject. This process is time-consuming and involves manual interaction. As the velocity of commerce is increasing, it’s very important to have a quicker solution to detect fraud. Our merchants want results fast. In microseconds!! Only machine learning techniques enable us to achieve that with the sort of confidence level needed to approve or decline a transaction. Machine learning can evaluate huge numbers of transactions in real time. It is continuously analyzing and processing new data. Moreover, an advanced model such as neural networks autonomously updating its models to reflect the latest trends.
- Scale – Machine learning algorithms and models become more effective with increasing data sets. Whereas in rule-based models the cost of maintaining the fraud detection system multiplies as customer base increases. Machine-learning improves with more data because the ML model can pick out the differences and similarities between multiple behaviors. Once told which transactions are genuine and which are fraudulent, the systems can work through them and begin to pick out those which fit either bucket. These can also predict them in the future when dealing with fresh transactions. There is a risk in scaling at a fast pace. If there is an undetected fraud in the training data machine learning will train the system to ignore that type of fraud in the future.
- Efficiency – Contrary to humans, machines can perform repetitive tasks. Similarly, ML algorithms do the dirty work of data analysis and only escalate decisions to humans when their input adds insights. ML can often be more effective than humans at detecting subtle or non-intuitive patterns to help identify fraudulent transactions. As discussed earlier, it can also help to avoid false positives. Moreover, unsupervised ML models can continuously analyze and process new data and then autonomously update its models to reflect the latest trends.
HOW TO DETECT FRAUD USING MACHINE LEARNING?

Fraud detection process
Fraud detection process using machine learning starts with gathering and segmenting the data. Then the machine learning model is fed with training sets to predict the probability of fraud.
Extract Data
Generally, the data will be split into three different segments – training, testing, and cross-validation. The algorithm will be trained on a partial set of data and parameters tweaked on a testing set. The performance of the data is measured using a cross-validation set. The high performing models will be then tested for various random splits of data to ensure consistency in results.
Provide Training sets
The main application of machine learning used in fraud detection is the prediction. We want to predict the value of some output (in this case, a boolean value that is true if the payment is fraudulent and false otherwise) given some input values (for example, the country the card was issued in and the number of distinct countries the card was used in the past day). The data that is used to train the ML models consists of records with both the output values for various input values. The records are often obtained from historical data.
Building Models
Building models is an essential step in predicting the fraud or anomaly in the data sets. We determine how to make that prediction based on previous examples of input and output data. We can further divide the prediction problem into two types of tasks:
- Classification
- Regression
1. Logistic Regression
Regression analysis is a popular, longstanding statistical technique that measures the strength of cause-and-effect relationships in structured data sets. Regression analysis tends to become more sophisticated when applied to fraud detection using machine learning due to the number of variables and size of the data sets. It can provide value by assessing the predictive power of individual variables or combinations of variables as part of a larger fraud strategy. In these techniques, the authentic transactions are compared with the fraud ones to create an algorithm. This model (algorithm) will predict whether a new transaction is fraudulent or not. For very large merchants these models are specific to their customer base, but usually, general models will apply.
2. Decision Tree
This is a mature machine learning algorithm family used to automate the creation of rules for classification tasks. Decision Tree algorithms can use for classification or regression predictive modeling problems. They are essentially a set of rules which are trained using examples of fraud that clients are facing. The creation of a tree ignores irrelevant features and does not require extensive normalization of the data. A tree can be inspected and we can understand why a decision was made by following the list of rules triggered by a certain customer. The output of the machine learning algorithm might be a model like the following decision tree. This gives a probability score of fraud based on earlier scenarios.

Reference: https://stripe.com/radar/guide
3. Random Forest
Random Forest technique uses a combination of multiple decision trees to improve the performance of the classification or regression. It allows us to smooth the error which might exist in a single tree. It increases the overall performance and accuracy of the model while maintaining our ability to interpret the results and provide explainable scores to our users. Random forest runtimes are quite fast, and they are able to deal with unbalanced and missing data. Random Forest weaknesses are that when used for regression they cannot predict beyond the range in the training data and that they may over-fit data sets that are particularly noisy. Of course, the best test of any algorithm is how well it works upon your own data set.

Reference: http://blog.citizennet.com/blog/2012/11/10/random-forests-ensembles-and-performance-metrics
4. Neural Networks
It is an excellent complement to other techniques and improves with exposure to data. The neural network is a part of cognitive computing technology where the machine mimics how the human brain works and how it observes patterns. The neural networks are completely adaptive; able to learn from patterns of legitimate behavior. These can adapt to the change in the behavior of normal transactions and identify patterns of fraud transactions. The process of the neural networks is extremely fast and can make decisions in real time.

Reference: http://www.predictiveanalyticstoday.com/fico-new-patents-fraud-detection-advanced-analytics/
LIMITATIONS OF USING MACHINE LEARNING FOR FRAUD DETECTION
Machine learning is not a panacea for fraud detection. It is a very useful technology which allows us to find patterns of an anomaly in everyday transactions. They are indeed superior to human review and rule-based methods which were employed by earlier organizations. But this technique of fraud detection has its own limitations:
1. Lack of inspectability
At Maruti Techlabs we maintain the backend machine learning model for our client. Thus we are required to explain the reasons for a buyer or seller being flagged as a fraudster and prevented from using the system. We also need to do this so that our client can confirm fraud and therefore train the system. In fact, machine learning is only as good as the human data scientists behind it. Even the most advanced technology cannot replace the expertise and judgment it takes to effectively filter and process data and evaluate the meaning of the risk score. So while we have eliminated this problem through rule-based techniques, lack of inspectability can be a drawback of certain other machine learning-based approaches.
2. Cold start
It takes a significant amount of data for machine learning models to become accurate. For large organizations, this data volume is not an issue but for others, there must be enough data points to identify legitimate cause and effect relationships. Without the appropriate data, the machines may learn the wrong inferences and make erroneous or irrelevant fraud assessments. It’s often better to apply a basic set of rules initially and allow the machine learning models to ‘warm up’ with more data. We often apply this approach with smaller datasets.
3. Blind to connections in data
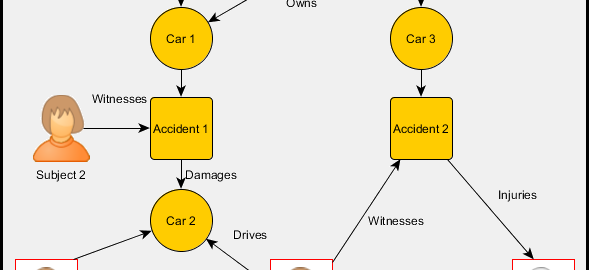
Machine learning models work on actions, behavior, and activity. Initially, when the dataset is small, they are blind to connections in data. The model can overlook a seemingly obvious connection such as a shared card between two accounts. To counter this we enhance our models with Graph networks. Graph technique can find multiple bogus actors for every single one prevented through scoring. Graph databases allow us to block suspect and bogus accounts before they have taken any fraudulent action. Following image shows a simple buyer insurance fraud case represented as a graph.

Ref: http://sparsity-technologies.com/blog/graph-database-use-case-insurance-fraud-detection/
Since machine learning is a very popular field among academicians as well as industry experts, there is a huge scope of innovation. Experimentation with different algorithms and models can help your business in detecting fraud. Machine learning techniques are obviously more reliable than human review and transaction rules. The machine learning solutions are efficient, scalable and process a large number of transactions in real time. But extracting data and training data sets for correct prediction is a tough task.
To detect suspicious activity, and more importantly to separate false alarms from true fraud, PayPal uses a homegrown AI engine built with open-source tools. As a result of this human and AI solution, Paypal has decreased its false alarm rate to half. But banks have been slow to adopt machine learning and AI solutions at a large scale. It’s because of the high infrastructural costs, strict regulations and risk of replacing existing technology. Nevertheless, the banks can start using machine learning solutions for the analysis of unstructured information such as monitoring social media and scrutinizing customer accounts for anomalies.
Business & Finance Articles on Business 2 Community
(53)
Report Post