— July 1, 2019
In my experience, I find that teams and organizations report many winning A/B tests with high uplifts, but somehow they don’t seem to bring those uplifts in reality. How come?
Five types of A/B test “wins” can exaggerate discovered uplifts. I use the acronym “de FACTO”:
- False winners;
- Anti-winners;
- Changing winners;
- Tricked winners;
- Overestimated winners.
These five types of winners show up in every experimentation program. I’ll describe why and how they cause exaggerated uplifts. But before I do, I want to emphasize that incorporating knowledge like this is just another step in your experimentation maturity.
Even though experimentation might not bring as much growth as you anticipated, not running trustworthy experiments is usually worse than incorrectly calculating their added value. A solid testing process is more important than accurately predicting how much profit you’ll get from it.
So keep increasing the quality, (statistical) trustworthiness, and velocity of your A/B tests. But when you want to deliver a realistic impression of their added value, have a skilled person from your team or agency correct the projected (or “discovered”) uplift to a more accurate “net value.”
A typical case of exaggerated uplifts
The “net profit” calculation is a better way to estimate the impact of the initial results we get from a series of A/B tests.
To give you an indication of the difference between the “discovered” and “net” uplifts, I use the following case of a fictitious company called “DeFacto Ltd.”
DeFacto’s CRO team (or CRO agency):
- Ran 100 experiments in the past 12 months, all server side;
- Found 25 winners, with an average measured 6% uplift, resulting in $ 100,000 extra margin per winner (calculated using a Bayesian calculator with a threshold of >90%);
- At an average cost of $ 5,000 per experiment (100 hours x $ 50);
- And—for the sake of simplicity—they’ve run all experiments with trustworthy sampling, obeyed the rules of trustworthy experimentation, and implemented all winners instantly at negligible costs.
- Moreover, I assume they tested with enough traffic, uplifts, and base conversion rates to have a pretty standard a priori power of 80%.
By adding up all 25 winners of $ 100,000, they’ve generated $ 2.5 million in extra revenue, with $ 500,000 in costs. That results in an ROI of 500% and a gross profit on DeFacto’s A/B tests of $ 2 million.
Note that I call the profits “gross profit.” Now, what happens when we correct for the five types of exaggerating winners? We get DeFacto’s “net profit,” the profit we expect in reality: about $ 1 million, or only 50% of the gross profit.
Let’s get to the five types of exaggerating winners that are responsible for this “net” calculation. I’ll start with the easiest and best-known one.
5 types of winners that require business-case corrections
1. False winners
The existence of “false discoveries” is well-known to experts in online optimization (false positives or Type-I errors). However, business cases are not always corrected for them.
A false winner occurs when your challenger (B) actually makes no difference but wins purely by coincidence. For example, the randomization caused more users with relatively high buying intent to end up in the challenger condition, resulting in a higher conversion rate.
With a 90% significance threshold, this is expected to happen with 10% of all challengers. In the case of DeFacto, we can calculate that roughly 79%(!) of the challengers bring no uplift in reality.
 You can run this same test at ABTestGuide.com.
You can run this same test at ABTestGuide.com.
So how many false winners do you discover when 79% of the experiments bring no uplift in reality? DeFacto did 100 experiments, 79 of which brought no value. Of those, 10% are expected to win by coincidence (90% significance). This results in 8 false winners (31% of all winners), 17 true positives, and 4 false negatives.

Uncovering false winners is of utmost importance for a realistic business case. The problem is not the cost side. The eight false discoveries cost “only” $ 40,000. The bigger issue is that 31% of these “winners” did not generate any uplift.
There are more reliable and advanced ways of correcting for false winners, but simply subtracting 31% of false winners from the $ 2.5 million uplift already provides a more realistic figure. DeFacto’s profit on the program roughly corrected for false winners is just over $ 1.2 million (61% of the presumed $ 2 million).
CRO experts usually know about the existence of false discoveries among their winners. The next step is to estimate how many false winners worsen site performance.
2. Anti-winners
Anti-winners (as I call them) are the devil’s version of the previous “false winners.” They happen when we have a “winner” that is actually a significant loser. Instead of increasing your success metrics, your challenger decreases them.
Again the challenger wins purely by coincidence. It is “just really bad luck.” The official term is “S-type error” (S from “Sign”), and they typically occur only when running low-powered experiments. (For more info on S-type errors, see either of these two articles.)
While a false winner costs money to build but does no other harm, an anti-winner does both—costing money and shrinking your revenue.
Anti-winners are usually rare in A/B test programs due to the relatively high power levels. In the case of DeFacto (power >80%), we’d expect 0% anti-winners.
However, if you experiment with very low power levels—small samples, low conversion rates, and/or small effect sizes—you should correct your business case for anti-winners.
3. Changing winners
The third type of winner one should correct for is a harder one (or, maybe, “softer” is more applicable): changing winners. A changing winner has a positive effect in the short term (i.e. during the experiment) but becomes inconclusive or even backfires in the long run.
Long-term effects in a CRO program often are not measured. Experiments run for a predetermined 1 to 4 weeks. After we find a winner, we “ship” it and show it to everyone, thereby losing the opportunity to measure long-term effects.
However, in behavioral science, there’s a decent body of evidence on interventions that bring uplifts in the short term and backfire in the long run. A well-known backfiring effect, for example, is when you shift your users’ motivation from “intrinsic” to “extrinsic.”
 Extrinsic motivators, like short-term discounts, can boost conversions in the near term but fall flat over longer periods.
Extrinsic motivators, like short-term discounts, can boost conversions in the near term but fall flat over longer periods.
Examples of “extrinsic” motivators are discounts, free extras, or gamification tactics. These external rewards temporarily heighten motivation and thereby show uplifts in A/B tests. Yet they can undermine intrinsic motivation in the long run and ultimately result in losses.
Activity trackers are a contemporary example. They tend to move our motivation from a sustainable, intrinsic drive to be active to an unsustainable, extrinsic reward for outperforming past metrics. (See this article by Jordan Etkin.)
It’s almost impossible to calculate which winners are only temporary successes. Hold-out groups are a potential (albeit complex and costly) solution. The simpler fix is to train your CRO team in behavioral science about short- versus long-term behavior change.
For now, let’s assume DeFacto had a behavioral scientist educating their CRO team who dissuaded them from testing temporary tactics and, as a result, helped them avoid “changing winners.”
4. Tricked winners
“Tricked winners” are less known and highly dependent on the maturity of a CRO team (or agency). A tricked winner is an experiment that reports a winner purely because something unfair happened in the experiment to favor the challenger.
The difference between “false winners” and “tricked winners” is that a false winner occurs when your challenger wins by coincidence in an otherwise trustworthy experiment. A tricked winner occurs because of untrustworthy experimentation.
A simple example: In an experiment, a technical bug caused the challenger to receive more repeat visitors than the control. Since repeat visitors have a higher conversion rate, the challenger wins. The challenger isn’t better; it had an unfair advantage. This typical example is called a “sample ratio mismatch” (SRM), and gurus like Ronny Kohavi have written advanced posts on the topic.
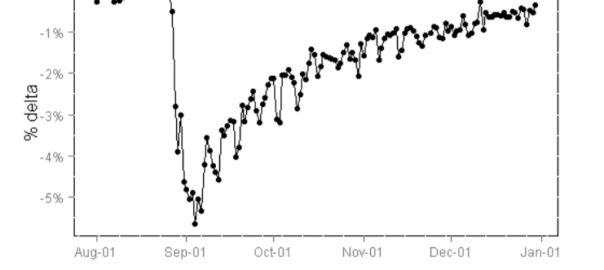
Other common causes of tricked winners are interaction and carryover effects. (These happen less frequently than SRM errors, in my experience.) Interaction effects occur when a challenger wins because the group was also exposed to a variation in another concurrent test.
Carryover effects happen when a challenger wins because one or both conditions still “suffer” from the effects of a previous experiment.

As Bing learned, the carryover effect can cause past experiments to impact a current a one. (Image source)
A skilled specialist can prevent tricked winners by checking for (or, even better, setting automated alerts for) these “unfair” effects. For now, let’s assume that DeFacto had alerts in place and no tricked winners.
5. Overestimated winners
The final type of winners are “overestimated winners.” Officially, they’re type-M errors (from “magnitude”). An overestimated winner exaggerates the magnitude of the uplift.
This happens all the time, in every experimentation program—just like false winners. Why? On average, tests with underestimated uplifts are less likely to win.
Here’s an example: Assume you have a good idea that causes a 5% uplift in reality. If you tested this idea nine times, it would result in different uplifts with an even spread around 5%. Unfortunately, the tests that measured low uplifts, like 1% and 2%, are not significant. The other seven that do record a winner have a higher average uplift than the true uplift.
Without correcting for these overestimations, your team or agency will confidently claim that their uplifts are larger in magnitude than they actually are. Increasing the power of your experiments will decrease the likelihood of “overestimated winners.”
In the case of DeFacto, with a power level of 80%, we can expect an overestimation of recorded uplifts by about 12%.
The effect of “overestimated winners” can be seen using this tool from Lukas Vermeer. You can also find more information in this article.
A final calculation for DeFacto
After we take “false winners” and “overestimated winners” into account, DeFacto’s net business case is more likely to be around $ 1.5 million in extra revenue, and their net profit on A/B testing is around $ 1 million—50% of the original $ 2 million.
We didn’t even correct for tricked winners, anti-winners, or changing winners, which may well plague other experimentation teams. All of these “winners” would further reduce net profit.
A final note: Some organizations use thresholds lower than 90% Bayesian. This can be wise if you statistically balance the value of winning experiments and the costs of inconclusive ones.
Your threshold reflects the risk of “false winners” that you find acceptable. Consider how much risk you’re willing to take while also keeping in mind that every implementation of a variation also entails costs.
If DeFacto would have used a 80% Bayesian threshold with all other results and metrics equal (like a winner ratio of 25%, not retesting winners, etc.), the net profit would go down to roughly zero—or less.
What can you do about false and exaggerated uplifts?
The most important thing to do is to keep experimenting. Heighten the trustworthiness of all experiments and winners, then start calculating the value of the program correctly.
Once those components are in place, you can scale your program based on a realistic business case. How do you do that?
1. Use trained statisticians.
Employ statisticians (or outsource the work). They can set up experimental designs and embed quality checks and alerts in your program to assure more trustworthy experimentation.
When they’re done with an initial setup, they can continue to embed and automate more advanced checks and analyses.
2. Hire behavioral experts.
Hire an experienced behavioral scientist (or scientists) who is trained in behavioral change, especially in short- versus long-term effects.
A nice extra: If you pick a good one, you’ll get extra knowledge on experimental design and statistics, since behavioral scientists are intensely trained in that as well.
3. Create an experimentation “Center of Excellence.”
When you scale your experimentation across teams, it’s best to build (or hire externally) an experimentation “Center of Excellence.” This center (or external experts) builds or develops your in-house experimentation platform.
A mature platform automates basic statistical checks and corrections to scale trustworthy experimentation based on a realistic estimation of the (net) value. Meanwhile, the experimentation teams can increase velocity without needing the statistical and behavioral skills.
4. Organize and act on your first-party customer intelligence.
If your teams run lots of trustworthy experiments, consider developing a behavioral intelligence Center of Excellence (or expand your experimentation Center of Excellence).
This center brings together all customer insights, builds customer behavior models based on meta analyses of experiments, and continuously grows the long-term impact of your validations.
Conclusion
Not running trustworthy experiments is usually worse than exaggerating their value. Sill, realize that A/B test winners bring less value than their reported uplifts, and lots bring no value at all.
You can create a more accurate estimate by correcting for five causes of exaggerated uplifts:
- False winners;
- Anti-winners;
- Changing winners;
- Tricked winners;
- Overestimated winners.
If you’re interested in calculating the “net value” of your experimentation program, you can use this A/B test calculator to get a sense of your percentage of false winners.
Digital & Social Articles on Business 2 Community
(64)