Can machine learning be applied to your PPC accounts to make them more efficient? Columnist David Fothergill describes how he utilized machine learning to find new keywords for his campaigns.

A key challenge when working on what we could term “large-scale” PPC accounts is efficiency. There will always be more that you could do if given an unlimited amount of time to build out and optimize an AdWords campaign; therefore, the trick is managing priorities and being efficient with your time.
In this post, I will talk about how concepts from machine learning could potentially be applied to help with the efficiency part. I’ll use keyword categorization as an example.
To paraphrase Steve Jobs, a computer is like “a bicycle for the mind.” The generally understood meaning of this statement is that, in the same way a bike can increase the efficiency of human-powered locomotion, computers can increase human mental productivity and output.
With the existentialism out of the way, let’s get to something tangible — We’ll explore here how relevant/valuable it could be to try and automate the process of placing new key phrases into an existing campaign.
What do we mean by machine learning?
As a definition of sorts that ties into our objectives, let’s consider the following to be true:
Machine learning is a method used to devise models/algorithms that allow prediction. These models allow users to produce reliable, repeatable decisions and results by learning from historical relationships and trends in data.
The benefit of “reliable, repeatable decisions” is the exact value that we’re interested in achieving in this case.
At a very high level, the objective of a machine learning algorithm is to output a prediction formula and related coefficients which it has found to minimize the the “error” – i.e., has been rigorously found to have the greatest predictive power.
The two main types of problems solved by machine learning applications are classification and regression. Classification relates to predicting which label should be applied to data, whereas regression predicts a continuous variable (the simplest example being taking a line-of-best-fit).

Categorization of keywords as a “classification” problem
With this in mind, my goal is to show how text classification could be used to programmatically decide where newly surfaced key phrases (e.g., from regular search query reports) can be placed. This is a trivial exercise, but an important one which can be time-consuming to keep on top of when you have an account of any scale.
A primary prerequisite for solving a classification problem is some already classified data. Given that an existing paid search account has keywords “classified” by the campaign they are in, this is a good place to begin.
The next requirement is some “features” that can be used to try and predict what the classification of new data should be. “Features” are essentially the elements on which a model is built — the predictor variables.
The simplest way to transform text data into a feature which is useful to an algorithm is to create a “bag of words” vector. This is simply a vector which contains a count of the number of times a word exists in a given document. In our case, we’re treating a keyword as a very, very short document.

Note: In practice, because our “documents” –i.e., keywords — are short, we could end up with a set of vectors that is not meaningful enough due to lack of diversity, but it’s out of the scope of this article to delve further into this.
Selecting a suitable algorithm
There is a wide range of different algorithmic approaches to solving a wide range of problem types. The below image illustrates this and also shows that there is a certain underlying logic which can help direct you toward a suitable choice.

As we’re in the area of text classification, let’s implement a Naive Bayes model to see if there is potential in this approach. It’s a pretty simple model (hence the “naive” part), but the fact that our feature set is pretty simple means it could actually pair up quite well with that.
I won’t go into any detail of how to apply this model, other than sharing how I would implement this in Python using the scikit-learn package — the reason being that I want to illustrate that it’s possible to leverage the power of machine learning’s predictive capabilities on only a few lines of code.*
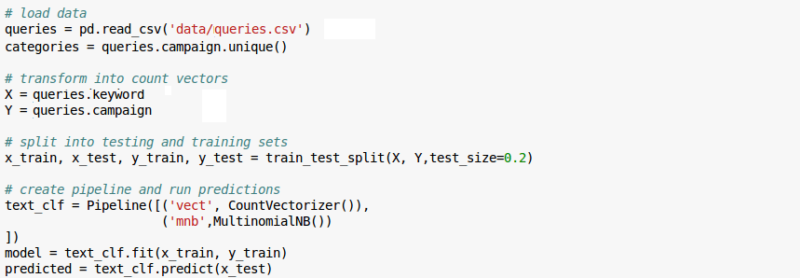
Below is a fairly exciting screen shot of my Jupyter Notebook going through the key steps of:
- loading the data with which to build the model (~20,000 keyphrases, pre-classified);
- splitting my data into training and testing subsets (This is necessary so we can “test” that our model will actually predict on future data and not just describe historical data);
- creating a basic pipeline which a) creates the features as discussed (CountVectorizer) and b) applies the selected method (MultinomialNB); and
- predicting values for the “test” set and gauging how accurate the labeling is vs. the “true” values.
*The caveat here is that I’m not a developer, but a mathematician who programs as a means to a mathematical end.
Conclusion
So, how effective is this? Using a simple measure of accuracy, this method correctly labeled/categorized 91 percent of “new” key phrases (4,431 out of 4,869).
Whilst this could be considered a decent result, we’d do a lot more tuning and testing before putting a model like this into practice.
However, I do believe it provides sufficient evidence that this is a relevant approach that can be taken forward to improve and automate processes — thus achieving the objective of gaining efficiency at scale via reliable, repeatable decision.
[Article on Search Engine Land.]
Some opinions expressed in this article may be those of a guest author and not necessarily Marketing Land. Staff authors are listed here.

Marketing Land – Internet Marketing News, Strategies & Tips
(103)
Report Post