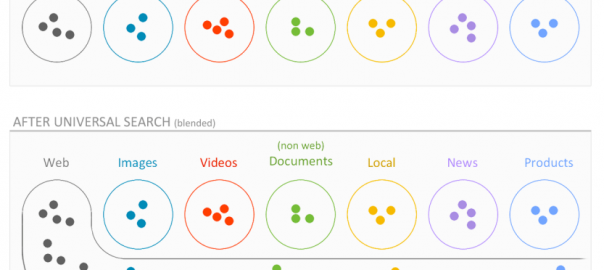
Google made an important innovation back in 2007: it mixed various types of search results together, delivering content on search engine results pages (SERPs) beyond mere websites and web pages. Under the new model images, products, videos, news and local businesses would appear within regular Google SERPs, so long as those media were sufficiently relevant to the query. This was called universal, or blended search.
Google’s engineers took an all-encompassing approach to this adjustment and blended all the media they had at once. The only types of media they didn’t integrate directly were standalone audio and video files (.mov, .wav, .mp3, etc.), presumably to avoid traffic detraction from other Google products like Youtube. But there was something else: another content type that didn’t occur to me until I read a research paper from Google on “table search”.

 Tables! Of course. This realization felt like spotting a well-camouflaged woodland animal in a naturesque landscape: it’s such an obvious value-add for a search engine and it’s been hidden in plain sight for years. Tables are a wonderful content type because they are, in many senses, structured data. They might not have a particular ontology the way semantic web markup does, but they do contain sets of data, annotated through captions and table headers (i.e., a table’s top row).
Tables! Of course. This realization felt like spotting a well-camouflaged woodland animal in a naturesque landscape: it’s such an obvious value-add for a search engine and it’s been hidden in plain sight for years. Tables are a wonderful content type because they are, in many senses, structured data. They might not have a particular ontology the way semantic web markup does, but they do contain sets of data, annotated through captions and table headers (i.e., a table’s top row).
In 2012 Google unveiled a special search engine they had built just for searching through tabular data. It was part of the Fusion Tables project which facilitates the merging and visualization of data within tables in Google Docs. In 2015, Google finally began integrating tables into web search, adding to the blended experience. But two important questions still come to mind: why did it take Google so long to integrate tables into web search and is it possible to use tables on a site to boost rankings? To answer this, we’ll need to delve a little deeper and understand how Google’s Table Search came to be.

Example of a query in Google’s Table Search Engine
The Problem of Bad Tables
At first glance, it would seem that tables that have headers are described in some detail through those headers. That would imply that part of the work is already done for Google and there’s no need to mine through text and extrapolate meaning the way Google does for web pages—tables appear to be a somewhat readily usable type of content. Unfortunately, as anyone familiar with web development in the 90’s and early 2000’s will tell you, there’s more to the story.
There are a vast quantity of “bad” tables out there that don’t contain any structured information. These tables were used in the early days of the Internet to aid in web page layout before CSS was widely adopted. Web designers would hide the borders around cells and stretch a table to form a template for the design of their site. Many websites that were designed in this way have never been updated, which means Google engineers were faced with the challenge of finding a way to programmatically differentiate between tables that contained useful data and tables that were used for web layout. This is especially challenging because some data-oriented tables contain images, while bad tables are sometimes used within a page otherwise designed in CSS.
Google used machine learning and a process of elimination to exclude many of these bad tables from their index. They had over 10 billion tables to process, 99% of which were bad. They found that good tables had certain features in common—and these are features content creators will be able to use to leverage table search in the future.
The Anatomy of a Good Table
 What do good tables have in common? As you might expect, they have headers, specified with the <th> tag and they include a <caption> which describes the table.
What do good tables have in common? As you might expect, they have headers, specified with the <th> tag and they include a <caption> which describes the table.
More importantly however, reliable tables have both surrounding content (which further describes what the table’s about) and a single “subject column” that serves as the central column, just as the header is the most important row (similar to a primary key in a database).
The subject column isn’t declared in HTML: Google figures this out on its own, and if it can find a reliable subject column with a high degree of confidence, there’s a very high chance that the table in question is of high quality and will be accepted into Google’s index as a reliable table.
Here’s an example of a high quality table with a subject column that’s been emphasized with CSS. This emphasis gives Google a strong indication that this is a useful table because:
- The subject column is made to stand out from the other columns, suggesting that the work may already be done; i.e., the subject is already identified.
- The subject column uses CSS to stylize content (as does the rest of the page), which implies that this table’s purpose has nothing to do with web layout.
It’s important to note that some legitimate tables that contain large amounts of useful data can theoretically have two subject columns. However, at this juncture Google’s isn’t able to identify such tables with a reasonable degree of accuracy, therefore a single, perspicuous subject column is our rule of thumb.
Tables in Google Web Search
Google’s gradually blending tables into web search. Unlike other types of content however, tables are blended into search results in two different ways. The first, as seen below, is a direct fragment from a table found on the web.

Unfortunately, at this time tables will only appear within search results for fact-seeking informational searches. Google also truncates the table to provide a clear answer to the query—and to leave room for other search results (and ads) above the fold. This is still a very new addition to Google SERPs and with time, tables will appear in an increasing amount of searches. The searches that are most likely to lead to a table within search results refer to the intersection of a table header or caption and an item in the subject column. For instance, the table above is captioned “Literacy Rates for Countries of the World” and we’re looking for the literacy rate for a specific item in the subject column: Canada.

Tables are also blended into search results in another fashion: through rich snippets. Rich snippets display additional data contained within a page on SERPs. These normally require some semantic markup like microdata to classify content on the page, but a certain type of table tends to work as a dependable alternative. A two column vertical table, such as those used in Wikipedia info boxes, will typically center around a very specific topic and directly assign values to data points. With only two columns in play there’s less need for interpretation and thus this kind of table serves as a great use case for rich snippets without any semantic markup (see left).
 Other Structured Web Content
Other Structured Web Content
It’s worth noting that Google’s looking into other forms of content on the web that have structure or a pattern to them, such as lists. It will be more difficult for a machine like Google to interpret and classify this data with a low error margin, but for some queries, we can already see some results using something like this in the wild (see right).
The Future of Tables in Search
Tables are a component of Google search that’s still in its infancy. While they may not present too many applicable advantages for SEO right now, this will change and now is the time to institutionalize them by publishing datasets and re-organizing content that’s suited for tables.
Tables can be used to declare structured data when a formal vocabulary for an item doesn’t exist yet. Moreover new experiments, such as search results that build a table on-the-fly for a specific query, hint at the notion that tables could play an increasingly important role in data classification and web search.
See here for more information, including an updated list of table ranking factors and a deeper understanding of the anatomy of a good table.
Also see the original paper from Google on this subject as well as their paper on Fusion Tables. Thanks to Bill Slawski from SEO By The Sea for first noticing and interpreting this.
(298)
Report Post