There have been a rash of tweets and blogposts recently talking about the problems with using averages in PPC marketing. For example, this one where Julie Bacchini argues that “averages are a sucky metric”:

While it’s true that sometimes averages can be very misleading, the problem with the above data set is the huge population variance and standard deviation in the sample.
In this post I want to talk about the math involved here and make a case for the value of averages, as well as respond to some of the criticism of reporting on averages that I’ve seen in the PPC community lately.
Variance, Standard Deviation and Coefficient of Variance
Sample variance is a measure of dispersion – by how much the values in the data set are likely to differ from the average value of your data set. It’s calculated by taking the average of the squares of the differences for each data point from the average. Squaring the differences ensures that negative and positive deviations do not cancel each other out.
So for client 1, just calculate the difference between 0.5% and the average change of 3.6%, then square that number. Do this for every client, then take the average of the variances: that’s your sample variance.

Sample Standard Deviation is simply the square root of the variance.
In simple terms, on average, the values in this data set typically fall 5.029% away from the overall average of 3.6% (i.e. the numbers are very dispersed), which means you can’t conclude much from this distribution.
A simplified way to estimate if your standard deviations are “too high” (assuming you’re looking for a normal distribution) is to calculate a coefficient of variance (or relative standard deviation) which is simply the standard deviation divided by the average.
What does this mean and why should we care? It’s about the value of reporting on averages. When WordStream does a study using client data, we don’t just compute averages from small data sets and make big conclusions – we care about the distribution of the data. If numbers are all over the place, we throw them out and try to segment the sample a different way (by industry, spend, etc.) to find a more meaningful pattern from which we can more confidently draw conclusions.
Even Meaningful Averages by Definition Include Values Above and Below the Average
Another line of criticism from the anti-average camp is the notion that an average doesn’t speak for the entire population. This is of course true, by definition.

Yes, averages contain data points that fall above and below the average value. But this isn’t a great argument for throwing out averages altogether.
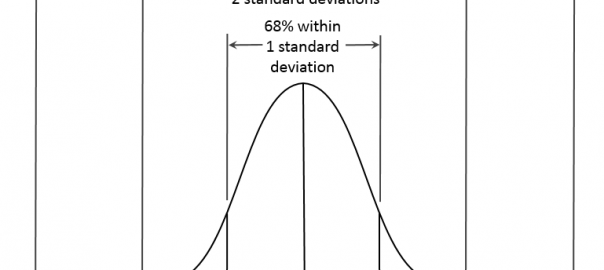
Assuming a normal distribution, you would expect approximately 68% of your data points to fall +/- 1 standard deviation from your average, 95% within +/- 2 standard deviations, and 99.7% within +/- 3 standard deviations, as illustrated here.

A typical normal distribution curve
As you can see, outliers certainly exist, though if you have a tight standard distribution in your dataset, they’re not as common as you might think. So if you’re careful about the math, averages can still be very useful information for the vast majority of advertisers.
In PPC Marketing, Math Wins
Let’s not throw averages out with the bathwater. After all, pretty much all of the performance metrics in AdWords like (CTR, CPC, Average Position, Conversion Rates, etc.) are reported as average values.
Instead of ignoring averages, let’s use the power of math to figure out if the average you’re looking at is meaningful or not.
Digital & Social Articles on Business 2 Community(67)